AI capability continues to improve at a remarkable pace as the frontier models race toward artificial general intelligence (AGI). But how close are we really to AI which can replace or substantially augment human knowledge workers?
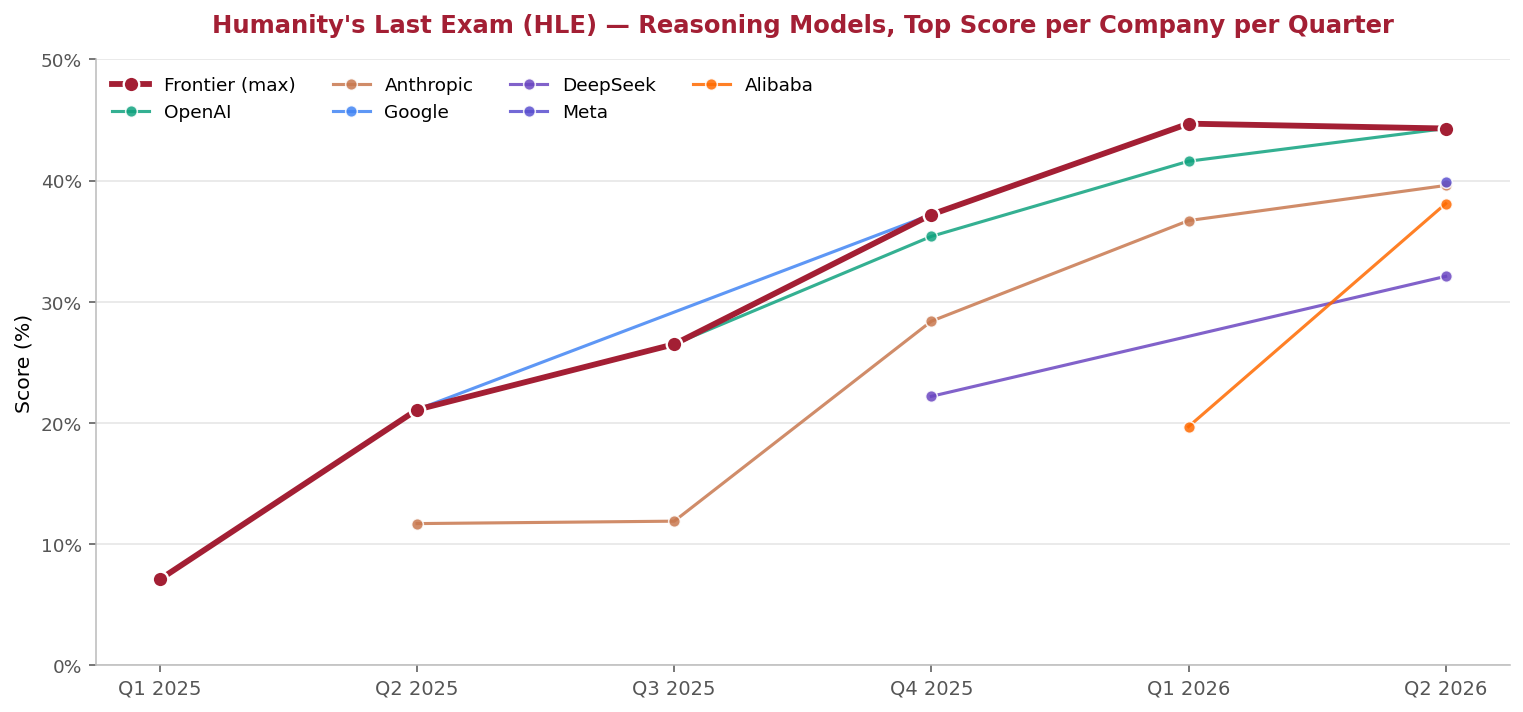
Humanity’s Last Exam (HLE) — Reasoning Models, Top Score per Company per Quarter | Source: Artificial Analysis HLE leaderboard, reasoning-models filter (snapshot May 24, 2026)
Frontier reasoning models scored just over 7% on Humanity’s Last Exam (“HLE”)[1] in January 2025 and reached the mid-40s by May 2026. Yet the top score still sits below 45%, meaning the best AI in the world still answers more than half of the questions on Humanity’s Last Exam incorrectly.
Saturation[2]: The Recurring Benchmark Pattern
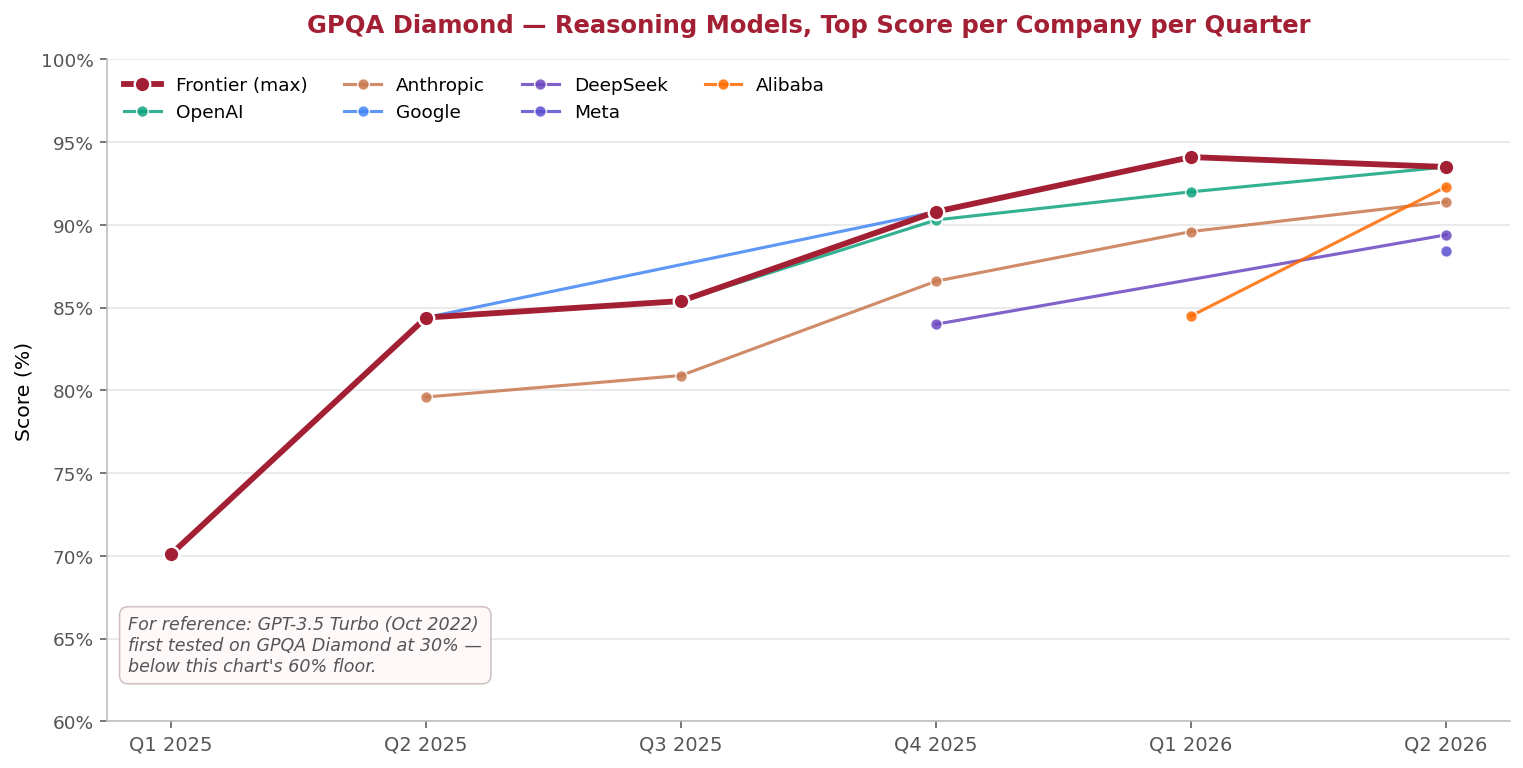
GPQA Diamond — Reasoning Models, Top Score per Company per Quarter | Source: Artificial Analysis GPQA Diamond leaderboard, reasoning-models filter (snapshot May 24, 2026)
GPQA Diamond — a 198-question graduate-level science benchmark introduced in late 2023 to test whether AI could match PhD-level domain experts — is approaching saturation. Frontier reasoning models now cluster in the 88–94% range, near the ceiling of what label noise and question ambiguity make statistically reliable. This is the recurring pattern in AI benchmarking: each new test is designed to be hard at release, then matched or exceeded within one to four years, forcing researchers to design the next ceiling. HLE was designed as that next ceiling.
| Benchmark | Released | Saturation Reached | Years to Saturation |
|---|---|---|---|
| GLUE | Apr 2018 | mid-2019 | ~1 year |
| SuperGLUE | May 2019 | mid-2021 | ~2 years |
| MMLU | Sep 2020 | Sep 2024 | ~4 years |
| HumanEval (coding) | Jul 2021 | early 2025 | ~3.5 years |
| GSM8K (math) | Oct 2021 | mid-2024 | ~2.5 years |
| MMLU-Pro | Jun 2024 | Nov 2025 | ~1.5 years |
| GPQA Diamond | Nov 2023 | Q1 2026 (approaching) | ~2.5 years |
| HLE (current frontier) | Jan 2025 | not yet (frontier ~45%) | — |
Each benchmark was designed to be difficult at release; frontier scores reached saturation within one to four years, forcing researchers to design the next ceiling. “Saturation” refers to frontier scores clustering inside the benchmark’s label-noise and ambiguity floor, making model differentiation statistically unreliable — it is not 100% accuracy. Source: AI research literature; CRE42 compilation from benchmark release papers and Artificial Analysis leaderboard data.
METR Time Horizon: Measuring Agentic (Autonomous) AI Capabilities
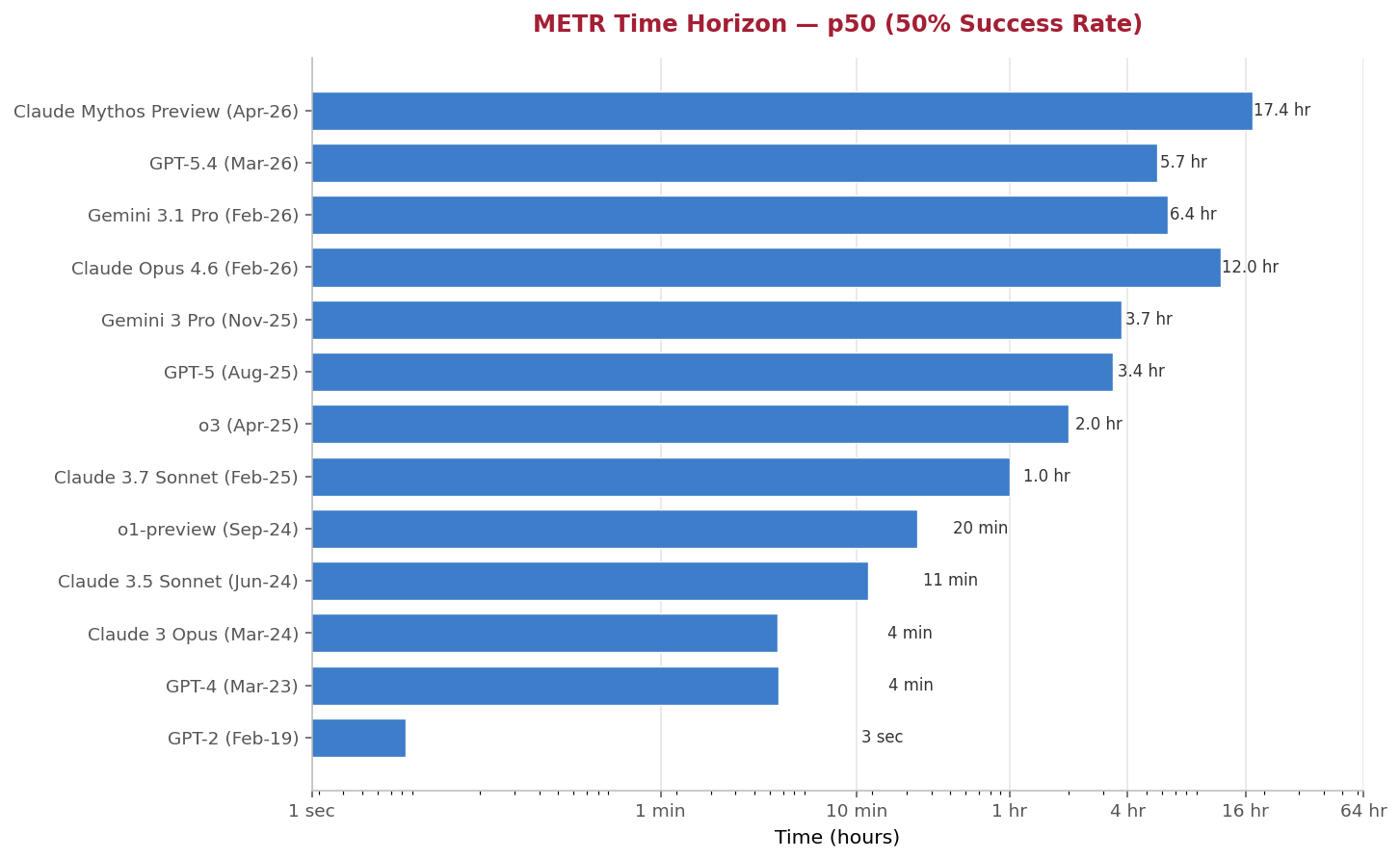
METR Time Horizon — 50% Success Rate (p50): How long a human-expert task an AI can complete autonomously half the time | Source: METR benchmark_results v1.1 dataset (Apr 6, 2026 release)
The METR Time Horizon chart[3] is a perfect illustration of the uncertainty surrounding AI and its potential to augment and/or replace white-collar workers. On one hand, AI is advancing at an unbelievable rate, basically doubling its abilities every few months and showing the potential for exponential growth into the future. On the other hand, the scoring mechanism of the test itself gives us a clue regarding AI’s most fundamental problems: intermittent reliability and hallucinations. The test measures the “task-completion time horizon,” defined by METR as “the task duration (measured by human expert completion time) at which an AI agent is predicted to succeed with a given level of reliability [in this case 50%].”[5] While going from less than five hours to 17+ hours in five months (Dec 2025 to Apr 2026) is extremely impressive, any human with a “success” rate of 50% (or even 80%) would not last long at real-life companies.[4] Anyone who uses AI for complex and iterative analysis can attest to the frequency of hallucinations and its apparent preference to make up facts and figures over asking clarifying questions. The models continue to improve in this aspect but still have a very long way to go before humans can be taken “out of the loop” for most professional processes.
The same models tested at the more demanding 80% success threshold (p80) typically run four to six times shorter than at p50:
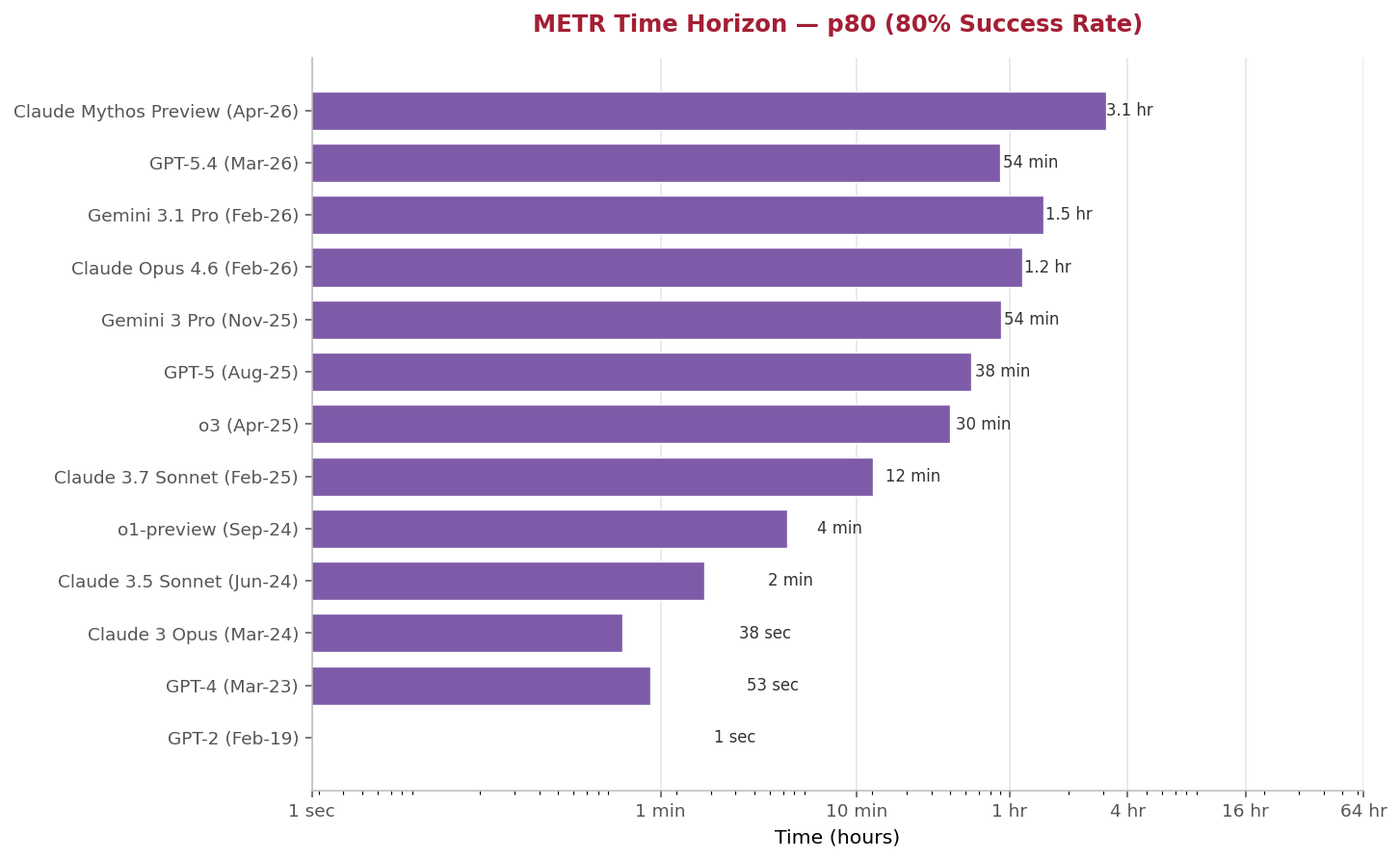
METR Time Horizon — 80% Success Rate (p80): Same task universe, higher reliability threshold | Source: METR benchmark_results v1.1 dataset (Apr 6, 2026 release)
What to Watch for in 2026 and Beyond
AI has demonstrated an ability to work through complex problems with novel strategies, empowering DeepMind to defeat world Go champion Lee Sedol in 2016, revolutionize protein folding prediction (earning the AlphaFold team a Nobel Prize in Chemistry in 2024), and most recently (May 2026) an internal OpenAI reasoning model offered a new solution to a well-known and previously misunderstood eighty-year-old geometry problem.[6] AI is exceptional at well-defined technical tasks like writing code, summarizing documents, and generating first-draft analyses, but most professional work involves iterative judgment, social negotiation, and an understanding of physical-world and organizational context.
The AI revolution will likely move faster than the previous three industrial revolutions but will still share a few common characteristics: (1) new technology adoption will be an iterative process as people and organizations learn to understand, use, and incorporate AI into their lives and workflow; (2) jobs will be augmented, replaced, and created in an ongoing process and affect different industries on different timelines and in different manners; and (3) the majority of today’s predictions and projections related to AI adoption and job displacement will look ridiculous in ten years — this is necessarily true because the range is so wide and variable.
Sources to Track AI Model Progress in 2026:
| Source | Report / Series | Frequency | Notes |
|---|---|---|---|
| Artificial Analysis | Benchmark leaderboards (HLE, GPQA, etc.) | Continuous | Comprehensive cross-benchmark leaderboard with reasoning-models filter; primary source for HLE and GPQA Diamond scores |
| METR | Time Horizons benchmark | Per model release | Measures how long an AI agent can autonomously complete human-expert tasks at p50 / p80 success rates |
| Anthropic Economic Index | AI usage by occupation | Quarterly | Actual usage data from millions of Claude conversations mapped to BLS occupational codes |
| Stanford HAI | AI Index Annual Report | Annual | Authoritative cross-domain compilation: benchmarks, investment, hardware, policy, and labor-market indicators |
| Stanford Digital Economy Lab | AI labor-market research | Ongoing | ADP payroll-data studies of AI's impact on employment by occupation and demographic |
| McKinsey | Global Survey on the State of AI | Annual | Enterprise AI adoption rates, use-case patterns, and productivity gains across industries and geographies |
[1] Humanity’s Last Exam, Center for AI Safety. A multidisciplinary 2,500-question benchmark covering mathematics, sciences, humanities, and engineering at expert level; released January 2025 with the explicit goal of resisting saturation longer than predecessors. ↩
[2] “Saturation” in this context means frontier scores cluster inside the label-noise ceiling of the benchmark, making it statistically unreliable for distinguishing top models. It is not equivalent to 100% accuracy. See benchmark-specific source papers and the Saturated Benchmarks tab in the linked workbook. ↩
[3] METR (Model Evaluation & Threat Research) times skilled human professionals on real software, ML, and cybersecurity tasks, then tests AI models on the same tasks. The p50 (50% success rate) and p80 (80% success rate) horizons identify the human task duration at which a model’s fitted success curve crosses the respective reliability threshold. Doubling time since 2023: approximately 4.2 months. ↩
[4] The current p50 frontier of 17.4 hours was set by Claude Mythos Preview (early), an Anthropic model evaluated by METR on April 6, 2026. METR’s own methodology page notes that “measurements above 16 hours are unreliable with our current task suite,” meaning the measurement infrastructure itself is at its practical limit at this point on the curve. Successor models and an updated task suite are expected; near-term frontier movement is therefore as much a function of METR’s ability to expand its test set as of model capability. ↩
[5] METR (Model Evaluation & Threat Research), “Measuring AI Ability to Complete Long Tasks.” Definition quoted from metr.org/time-horizons. ↩
[6] The unit-distance problem asks the maximum number of point pairs at distance exactly 1 that can be formed by N points in the plane. Erdős’s 1946 lower bound, based on square-grid constructions, was widely believed to be essentially optimal. OpenAI’s internal reasoning model produced an infinite family of constructions yielding a polynomial improvement, drawing on algebraic number theory in a way human researchers had not pursued. The proof was externally verified and a companion paper authored by human mathematicians. Since January 2026, AI has reportedly contributed to solving fifteen previously-open Erdős problems. ↩
Sources
[1] Artificial Analysis HLE leaderboard. artificialanalysis.ai
[2] Artificial Analysis GPQA Diamond leaderboard. artificialanalysis.ai
[3] Center for AI Safety, Humanity’s Last Exam. cais.org/hle
[4] Rein, Hou, et al. “GPQA: A Graduate-Level Google-Proof Q&A Benchmark.” arXiv:2311.12022 (Nov 2023).
[5] Wang, Singh, et al. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.” ICLR 2019.
[6] Hendrycks, Burns, et al. “Measuring Massive Multitask Language Understanding” (MMLU). ICLR 2021.
[7] Wang, Ma, et al. “MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark.” 2024.
[8] Chen et al. “Evaluating Large Language Models Trained on Code” (HumanEval). arXiv:2107.03374 (2021).
[9] Cobbe et al. “Training Verifiers to Solve Math Word Problems” (GSM8K). arXiv:2110.14168 (2021).
[10] METR, “Measuring AI Ability to Complete Long Tasks” (Mar 2025); METR benchmark_results v1.1 dataset (Apr 2026). metr.org/time-horizons
[11] OpenAI, “An OpenAI Model Has Disproved a Central Conjecture in Discrete Geometry” (May 2026). openai.com
[12] The Nobel Prize in Chemistry 2024, awarded to Demis Hassabis, John Jumper, and David Baker. nobelprize.org
[13] Silver et al., “Mastering the game of Go with deep neural networks and tree search” (AlphaGo). Nature 529 (Jan 2016).
[14] Jumper et al., “Highly accurate protein structure prediction with AlphaFold.” Nature 596 (Aug 2021); Varadi et al., “AlphaFold Protein Structure Database in 2024” (214M+ structures).